June 2024 Update
Another month, another Climbuddy progress update!
Starting from this one onward, each update will be separated into two sections: an #App section, which will cover the visible climbuddy.com app changes, and a #Tech section, which explores the things happening under the hood.
Let’s dive in! 🌊
App
Work is well underway for the newest release 0.3, which brings many improvements to the current UI, as well as a number of must-have features (mainly account-related things, as well as repeats).
The projected release date is next month and will likely be met, unless something catches on fire.
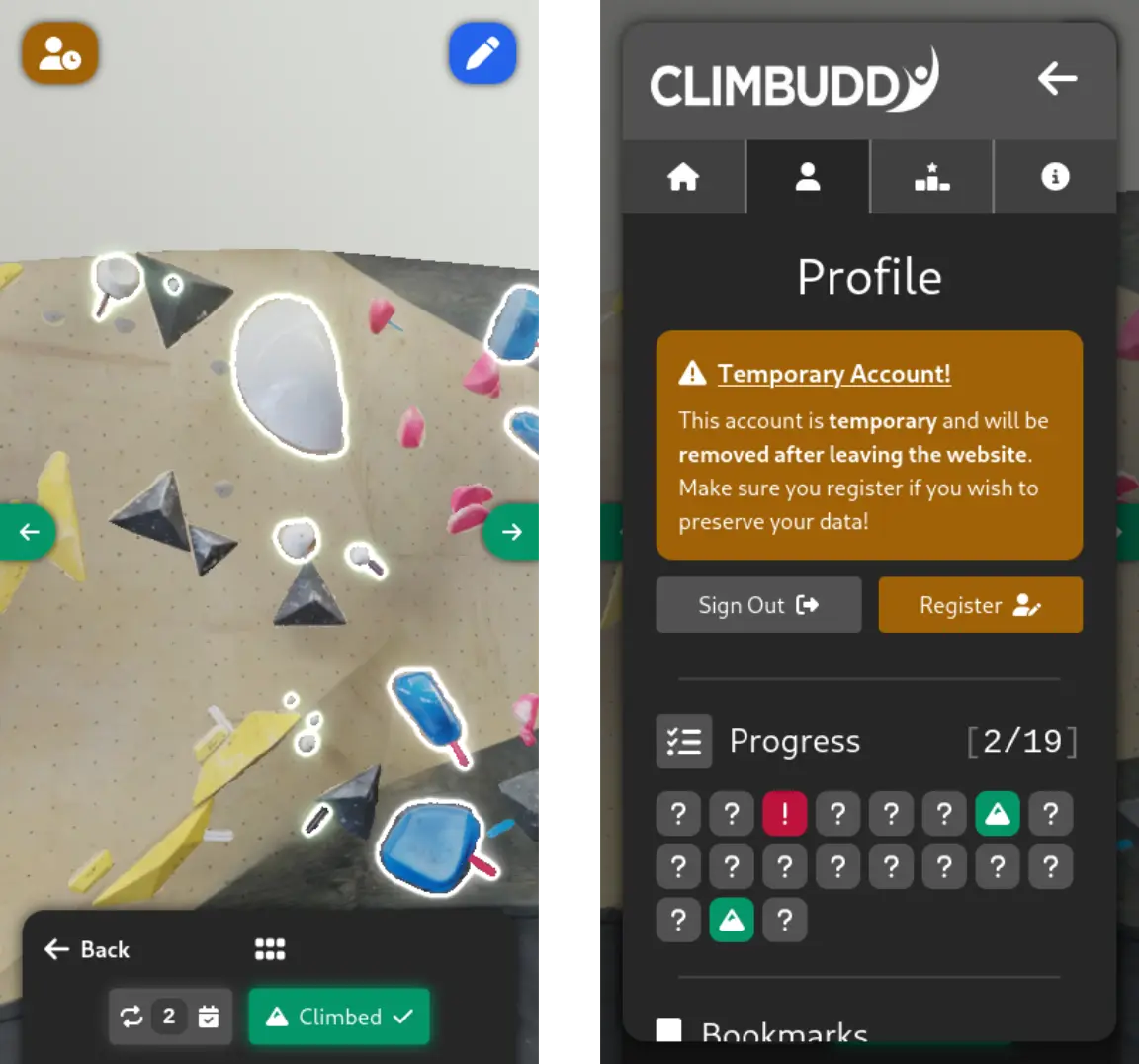
0.3, with the new repeat activity (left) and temporary account (right).The exact set of features that will be implemented in the next version (modulo minor things) can be found in the roadmap section of this page.
Tech
Route detection
Route detection is one of the most important issues that we need to solve in order to achieve full automation. The approach we are going for at the moment looks as follows:
- determine hold color via a neural network
- find same-colored routes via graph clustering
For now, we’ve done experiments on the feasibility of (1) and, unsurprisingly, it works really well since detecting colors is a rather simple task. We’re again using YOLOv8, this time as the classification task.
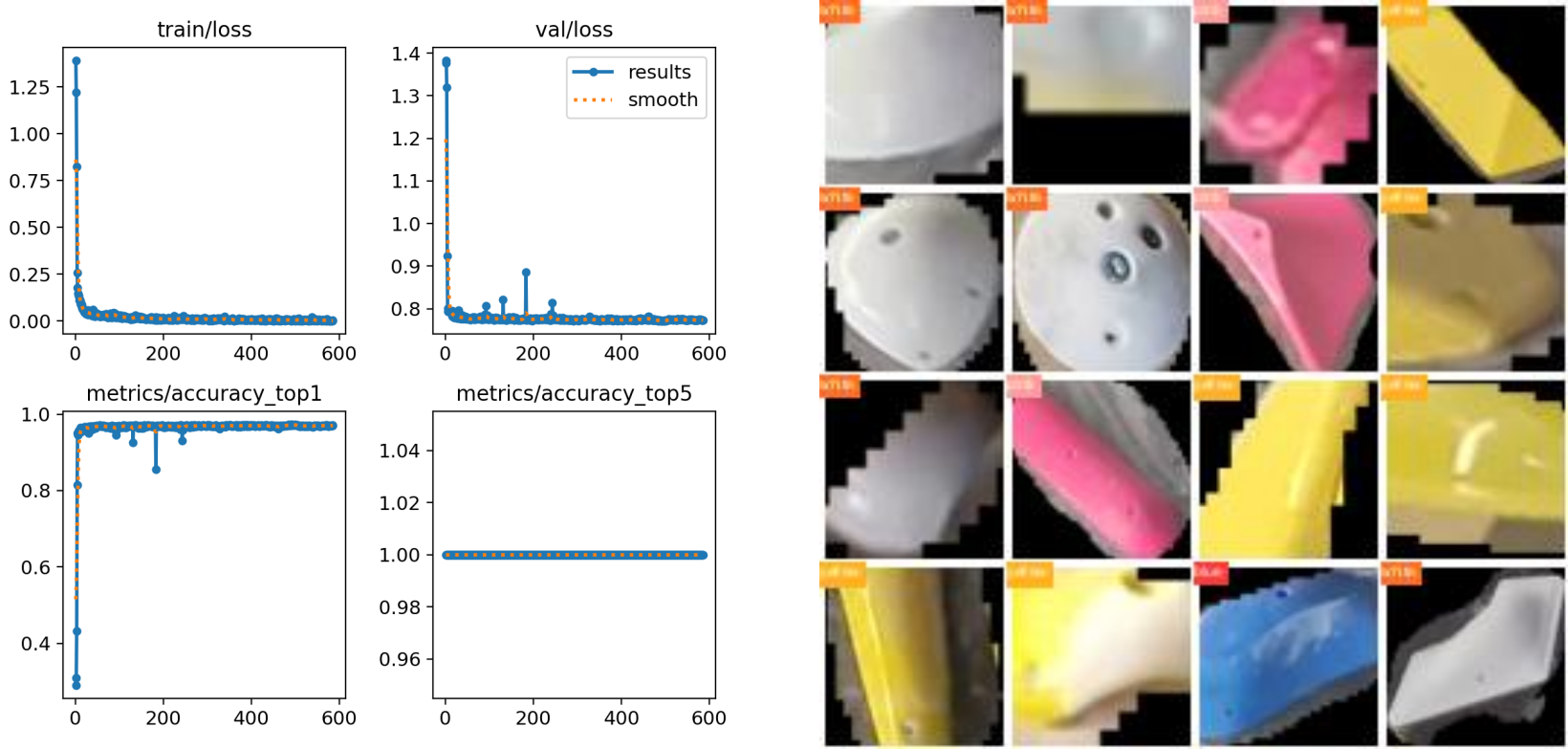
We will have to do many more tests on a larger set of images, but the initial results look great!
Parallelization
Since our priority is make Climbuddy usable as fast as possible, there are many places left in the current codebase for optimization.
We’ve decided to tackle the easier ones by parallelizing a significant number of tasks using Python’s multiprocessing module.
This is rather simple to accomplish – for example:
# No Multiprocessing
start_time = time.time()
for path in images:
_ = detect_aruco_markers(path, DICT_4X4_50)
print(f"No multiprocessing: {time.time() - start_time:.1f} seconds.")
# Multiprocessing
start_time = time.time()
with Pool() as pool:
for _ in pool.starmap(
detect_aruco_markers,
zip(images, [DICT_4X4_50] * len(images)),
):
pass
print(f"Multiprocessing: {time.time() - start_time:.1f} seconds.")
No multiprocessing: 29.1 seconds.
Multiprocessing: 6.1 seconds.
A nice speed increase by a factor of 4.7x!
This is just an example of how we used multiprocessing and there are many more things we will try to optimize in the future – right now, we’re still in the 10% of the work for 80% of the result and so achieving speedups like this is still rather simple.
Using SAM
We’ve also tried to address issues with the quality of segmentation masks. At the moment, they are essentially automatically generated from projecting from a 3D mesh to the image, which introduces inaccuracies due to the finite size of triangles and mismatched camera positions. Luckily, we can remedy this by using the Segment Anything Model (SAM), which is a general approach for segmenting any image, requiring points or bounding boxes as inputs for detecting the objects.
A sample result can be seen in figure below (using only bounding boxes of the original masks).

This is a promising approach that we will try to explore further as we find better ways of training the hold detection networks; at the moment, there are many instances in which it doesn’t work great and makes the segmentation mask much worse.
Team Climbuddy